Technical Approach
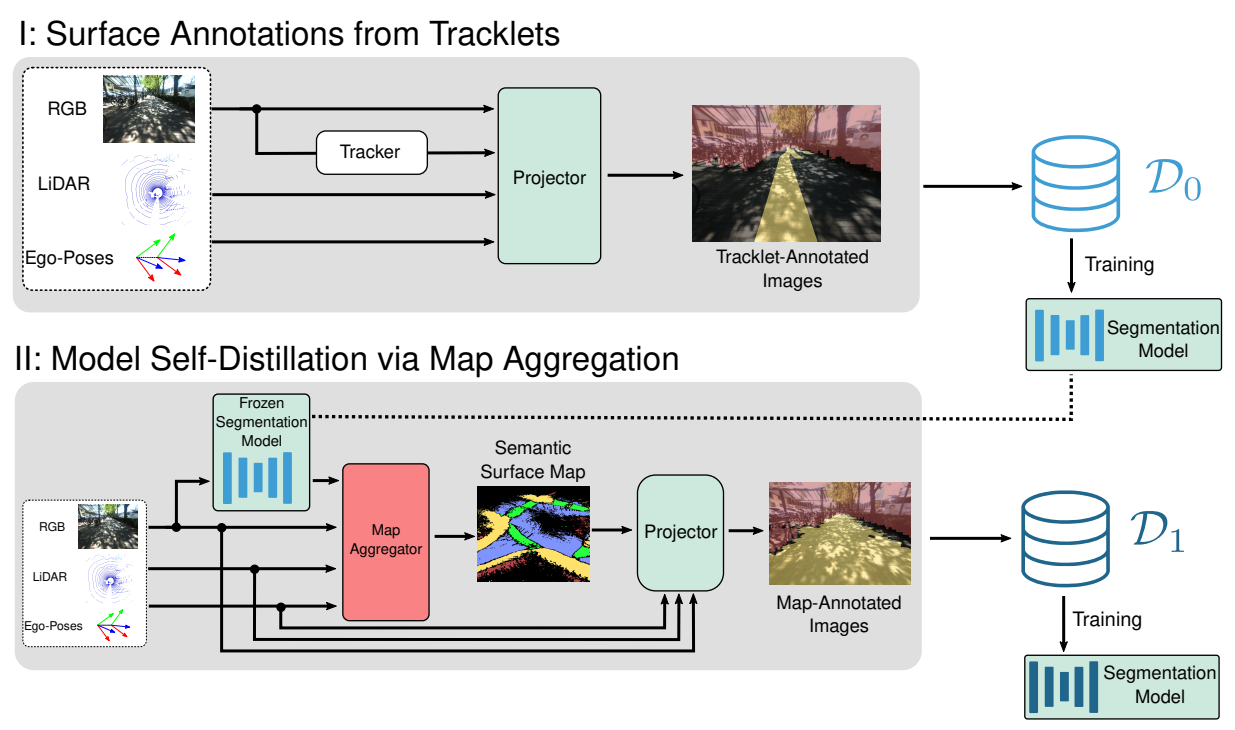
Robustly classifying ground infrastructure such as roads and street crossings is an essential task for mobile robots operating alongside pedestrians. While many semantic segmentation datasets are available for autonomous vehicles, models trained on such datasets exhibit a large domain gap when deployed on robots operating in pedestrian spaces. Manually annotating images recorded from pedestrian viewpoints is both expensive and time-consuming. To overcome this challenge, we propose TrackletMapper, a framework for annotating ground surface types such as sidewalks, roads, and street crossings from object tracklets without requiring human-annotated data. To this end, we project the robot ego-trajectory and the paths of other traffic participants into the ego-view camera images, creating sparse semantic annotations for multiple types of ground surfaces from which a ground segmentation model can be trained. We further show that the model can be self-distilled for additional performance benefits by aggregating a ground surface map and projecting it into the camera images, creating a denser set of training annotations compared to the sparse tracklet annotations. We qualitatively and quantitatively attest our findings on a novel large-scale dataset for mobile robots operating in pedestrian areas.